










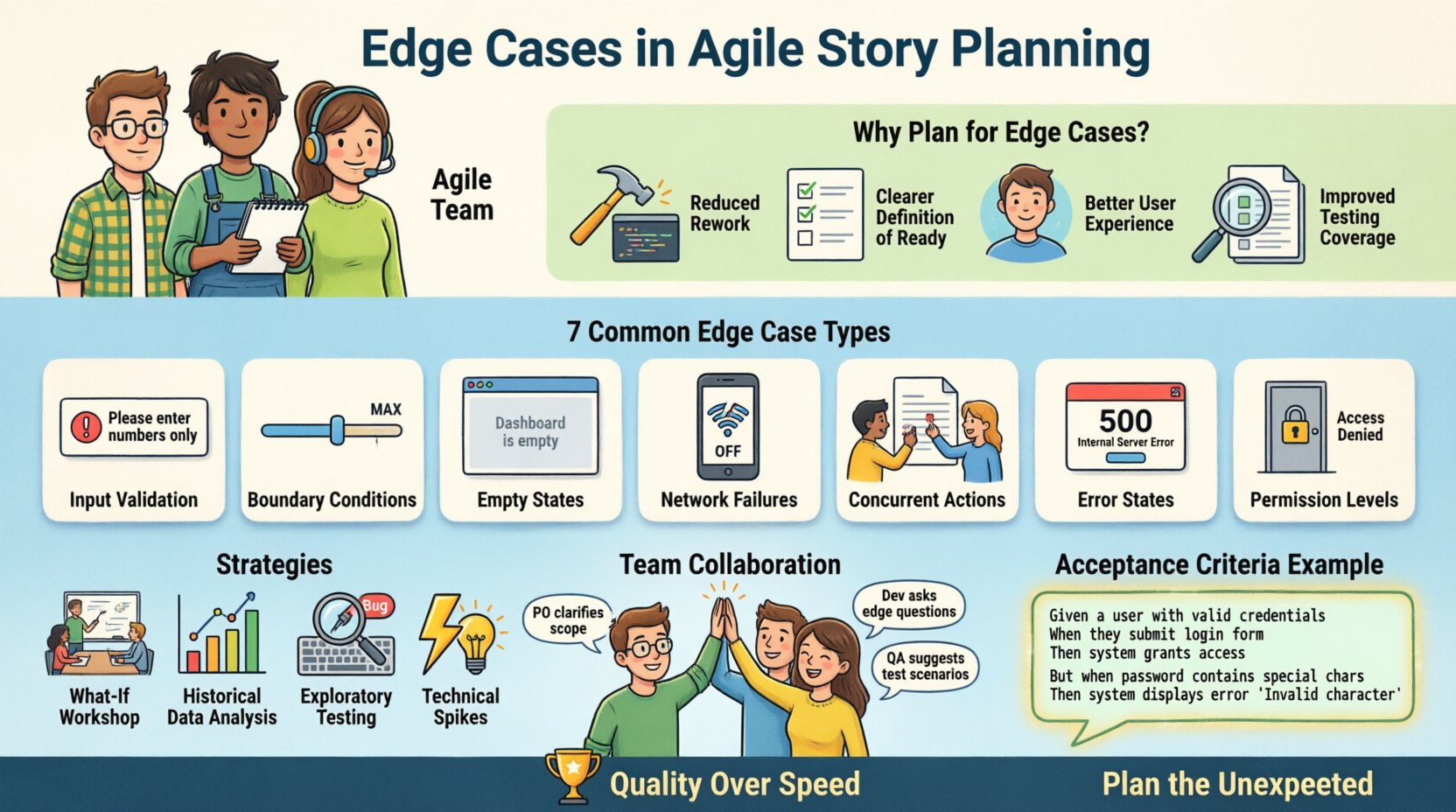
В быстром мире разработки программного обеспечения методологии Agile делают акцент на быстрой доставке ценности. Однако скорость без точности часто приводит к техническому долгу и недовольству пользователей. Одной из ключевых областей, где качество часто страдает, является этап планирования историй пользователей. В частности, игнорирование крайних случаев может привести к системам, которые работают при идеальных условиях, но выходят из строя при реальных сценариях.
Крайние случаи — это сценарии, выходящие за рамки нормального, ожидаемого поведения системы. Они часто представляют границы функциональности, состояния ошибок или редкие условия, с которыми пользователи могут столкнуться. Когда эти случаи игнорируются при планировании истории, команда разработчиков сталкивается с повторной работой, задержками релизов и разочарованными заинтересованными сторонами.
В этой статье рассматривается, как эффективно выявлять, планировать и управлять крайними случаями в историях пользователей в Agile. Мы рассмотрим практические стратегии, критерии приемки и методы командной работы, которые обеспечивают надежную доставку программного обеспечения без замедления рабочего процесса.
🤔 Что такое крайние случаи в историях пользователей?
Крайний случай — это ситуация, при которой ввод пользователя или состояние системы выходят за пределы типичного диапазона работы. В контексте истории пользователя это вопросы «а если», которые часто забывают при первоначальной разработке критериев приемки.
Рассмотрим историю о «Входе в систему». Путь успеха — ввод действительного имени пользователя и пароля для доступа к панели управления. Крайние случаи включают:
- Ввод имени пользователя со специальными символами.
- Ввод пароля, который слишком короткий.
- Ввод правильных учетных данных, но при этом учетная запись заблокирована из-за слишком большого количества неудачных попыток.
- Ввод учетных данных при отсутствии подключения к сети.
- Ввод пустого поля имени пользователя.
Если эти сценарии не будут рассмотрены при планировании, разработчик может реализовать путь успеха и оставить остальное на потом. Это приводит к возникновению «спайков» (задач с ограниченным временем на исследование), которые нарушают работу спринта, или хуже — к багам, попадающим в продакшн.
🚨 Почему игнорирование крайних случаев снижает скорость
Многие команды пропускают крайние случаи, чтобы сэкономить время. Они считают, что смогут решить их после создания основной функции. Такой подход часто создает узкое место. Вот почему планирование крайних случаев необходимо для поддержания скорости работы:
- Снижение повторной работы:Выявление ограничений на раннем этапе предотвращает написание кода, который потребуется переписывать. Исправление логической ошибки на этапе проектирования дешевле, чем исправление в продакшене.
- Четкое определение готовности:История с четко определенными крайними случаями действительно «готова» к разработке. Разработчики не должны останавливаться и задавать уточняющие вопросы в середине спринта.
- Улучшенное покрытие тестами:Команды QA могут создавать всесторонние тестовые сценарии, если крайние случаи документированы в истории. Это снижает количество сообщений об ошибках, подаваемых в ходе спринта.
- Улучшенный пользовательский опыт:Пользователи не заботятся о пути успеха. Они заботятся о том, что происходит, когда что-то идет не так. Грамотное управление крайними случаями формирует доверие.
📊 Распространенные типы крайних случаев, которые нужно учитывать при планировании
Чтобы помочь командам не забывать, что нужно учитывать, полезно классифицировать крайние случаи. В следующей таблице перечислены распространенные категории и примеры, актуальные для общего программного обеспечения.
| Категория | Описание | Пример сценария |
|---|---|---|
| Проверка ввода | Обработка данных, выходящих за пределы ожидаемых форматов. | Ввод текста в числовое поле. |
| Граничные условия | Проверка пределов диапазонов данных. | Максимальное количество символов в текстовом поле. |
| Состояния пустоты | Как выглядит система, когда данных нет. | Панель мониторинга без недавней активности. |
| Сбои в сети | Поведение системы при потере подключения. | Отправка формы в автономном режиме. |
| Параллельные действия | Несколько пользователей или систем, действующих одновременно. | Два пользователя пытаются отредактировать одну и ту же запись. |
| Состояния ошибок | Обработка сбоев системы или внешних сервисов. | Платежный шлюз возвращает ошибку таймаута. |
| Уровни разрешений | Контроль доступа для разных ролей пользователей. | Обычный пользователь, пытается получить доступ к настройкам администратора. |
Просмотр этого списка во время уточнения бэклога может значительно улучшить качество историй.
🛠 Стратегии выявления граничных случаев
Выявление не должно быть случайной деятельностью. Для этого требуется структурированный подход во время сессий планирования. Вот несколько техник, которые помогут выявить потенциальные граничные случаи.
1. Рабочее совещание «А если…»
Во время уточнения бэклога выделите определённую часть сессии для вопросов «А если…?». Владелец продукта или модератор проводит команду по пути пользователя и останавливается на каждом этапе, чтобы спросить, что может пойти не так.
- А если пользователь закроет браузер посередине процесса?
- А если база данных отключена?
- А если загрузка файла больше, чем разрешает сервер?
Запись этих ответов непосредственно в заметки к истории гарантирует, что они не будут утеряны.
2. Анализ исторических данных
Посмотрите отчёты об ошибках из предыдущих спринтов. Многие граничные случаи — это повторяющиеся проблемы, которые уже возникали в продакшене. Если определённая ошибка произошла в прошлом месяце, она должна быть явно учтена при планировании текущей истории.
3. Исследовательское тестирование
Перед началом разработки дайте команде QA или разработчикам немного времени на изучение приложения. Сознательное нарушение работы приложения может выявить крайние случаи, которые не были учтены при документировании.
4. Технические спайки
Для сложных функций может потребоваться технический спайк. Это ограниченное по времени исследование, целью которого является понимание возможности обработки конкретных крайних случаев. Результатом не является код, а скорее рекомендация по обработке ситуации.
📝 Написание критериев приемки для крайних случаев
Критерии приемки — это условия, которые должны быть выполнены, чтобы история считалась завершенной. Это договор между командой и владельцем продукта. Крайние случаи должны быть включены сюда.
При написании этих критериев избегайте расплывчатой формулировки. Используйте конкретные условия.
- Плохо: «Система должна обрабатывать ошибки».
- Хорошо: «Если API возвращает ошибку 500, отобразите общее сообщение «Что-то пошло не так» и попробуйте повторно установить соединение через 5 секунд».
Использование синтаксиса, основанного на поведении (BDD), например, Gherkin, также может помочь четко структурировать эти критерии.
Пример: синтаксис Gherkin для крайних случаев
Допустим, пользователь находится на странице оформления заказа И шлюз оплаты недоступен Когда пользователь нажимает «Оплатить сейчас» То система должна отобразить ошибку «Сервис недоступен» И позволить пользователю повторить попытку или отменить операцию
Этот формат заставляет команду думать о предусловиях (Допустим), действии (Когда) и результате (То), включая состояния ошибок.
🛡 Определение готовности (DoR)
Определение готовности — это чек-лист критериев, которые должна выполнить история пользователя перед тем, как войти в спринт. Включение крайних случаев в DoR гарантирует, что истории не будут перенесены в разработку без должного планирования.
Надежное определение готовности для обработки крайних случаев может включать:
- Четко определены ли основные пути работы?
- Были ли выявлены все основные состояния ошибок?
- Есть ли критерии приемки для пустых состояний?
- Было ли проанализировано влияние на существующие данные?
- Был ли проверен контроль доступа командой по безопасности?
Если история не может соответствовать этим критериям, она должна оставаться в бэклоге. Извлечение её в работу без выполнения этих условий создает риск незавершенной работы.
🤝 Сотрудничество между ролями
Выявление крайних случаев — это не только обязанность разработчиков. Это требует сотрудничества всей команды продукта.
Владельцы продукта
Владельцы продукта понимают бизнес-ценность и контекст пользователя. Они наиболее хорошо подходят для выявления сценариев, нарушающих бизнес-логику. Например, пользователь может попытаться приобрести товар, когда его кредитная карта просрочена. Это бизнес-крайний случай.
Разработчики
Разработчики понимают архитектуру системы. Они знают, где система уязвима. Они могут выявлять технические крайние случаи, такие как гонки данных или ограничения памяти.
Обеспечение качества
Инженеры по качеству обучены ломать вещи. Они должны просмотреть пользовательские истории до начала спринта, чтобы убедиться, что крайние случаи можно протестировать. Если сценарий нельзя протестировать, значит, он недостаточно хорошо определён.
⚙️ Управление техническим долгом из-за крайних случаев
Иногда обработка крайнего случая требует значительного объёма работы, который нарушает поток функций. Это может привести к техническому долгу. Важно управлять этим балансом.
- Приоритизация по риску: Не все крайние случаи одинаковы. Сбой входа в систему — это высокий риск. Незначительная проблема форматирования в редко используемом отчёте — низкий риск. Приоритизируйте по влиянию.
- Откладывайте с планом: Если крайний случай низкого риска сейчас обработать нельзя, зафиксируйте его. Добавьте его в список «Известные проблемы» и запланируйте на будущий технический спайк.
- Регулярно рефакторьте: Выделяйте часть каждого спринта на рефакторинг. Это предотвращает превращение обработки крайних случаев в огромный, неподдерживаемый блок кода.
📈 Метрики для непрерывного улучшения
Чтобы убедиться, что процесс планирования улучшается, отслеживайте конкретные метрики, связанные с крайними случаями.
- Коэффициент утечки багов: Сколько багов, связанных с крайними случаями, обнаруживается в продакшене? Высокий показатель указывает на недостаточность планирования.
- Переработка истории: Как часто истории возвращаются в бэклог из-за отсутствующих критериев приёма?
- Процент прохождения тестов QA: Какой процент тестовых случаев проходит с первого запуска? Низкий показатель указывает на неясные требования.
Рассмотрение этих метрик на ретроспективе может помочь команде скорректировать свои привычки планирования.
🧭 Культурный сдвиг: качество важнее скорости
Наконец, самым важным фактором является культура. Если команда чувствует давление срочно выпускать продукт, крайние случаи будут игнорироваться. Руководство должно подчёркивать, что качество — это функция, а не после мысли.
Когда член команды выявляет крайний случай, который задерживает релиз, его следует поощрять за это, а не наказывать. Это стимулирует проактивное планирование и снижает страх замедления.
🔄 Продолжительная проработка
Выявление крайних случаев — не одноразовое событие. По мере развития приложения появляются новые крайние случаи. Регулярные сессии проработки бэклога должны возвращаться к старым историям, чтобы проверить, не нужно ли добавить новые сценарии.
Например, новая интеграция с сервисом сторонней компании может привести к новым проблемам с задержкой сети, которые нужно учитывать в существующих историях. Постоянная проработка поддерживает актуальность бэклога и надёжность системы.
✅ Обобщение
Планирование крайних случаев — фундаментальная дисциплина в разработке программного обеспечения по Agile. Это требует усилий на старте, но окупается меньшей переработкой, лучшим пользовательским опытом и стабильными системами. Используя структурированные методы, такие как семинары «А что, если», чёткие критерии приёма и надёжное определение готовности, команды могут эффективно управлять сложностью.
Помните, что скорость без качества — это иллюзия. Вложение времени в планирование неожиданного гарантирует, что команда сможет последовательно и надёжно предоставлять ценность. Каждая история — это возможность создать более устойчивый продукт.
Начните с малого. Выберите одну предстоящую историю и проанализируйте её крайние случаи. Попросите команду проверить «счастливый путь». Скорее всего, вы найдёте возможности улучшить качество работы до того, как будет написана первая строка кода.
