











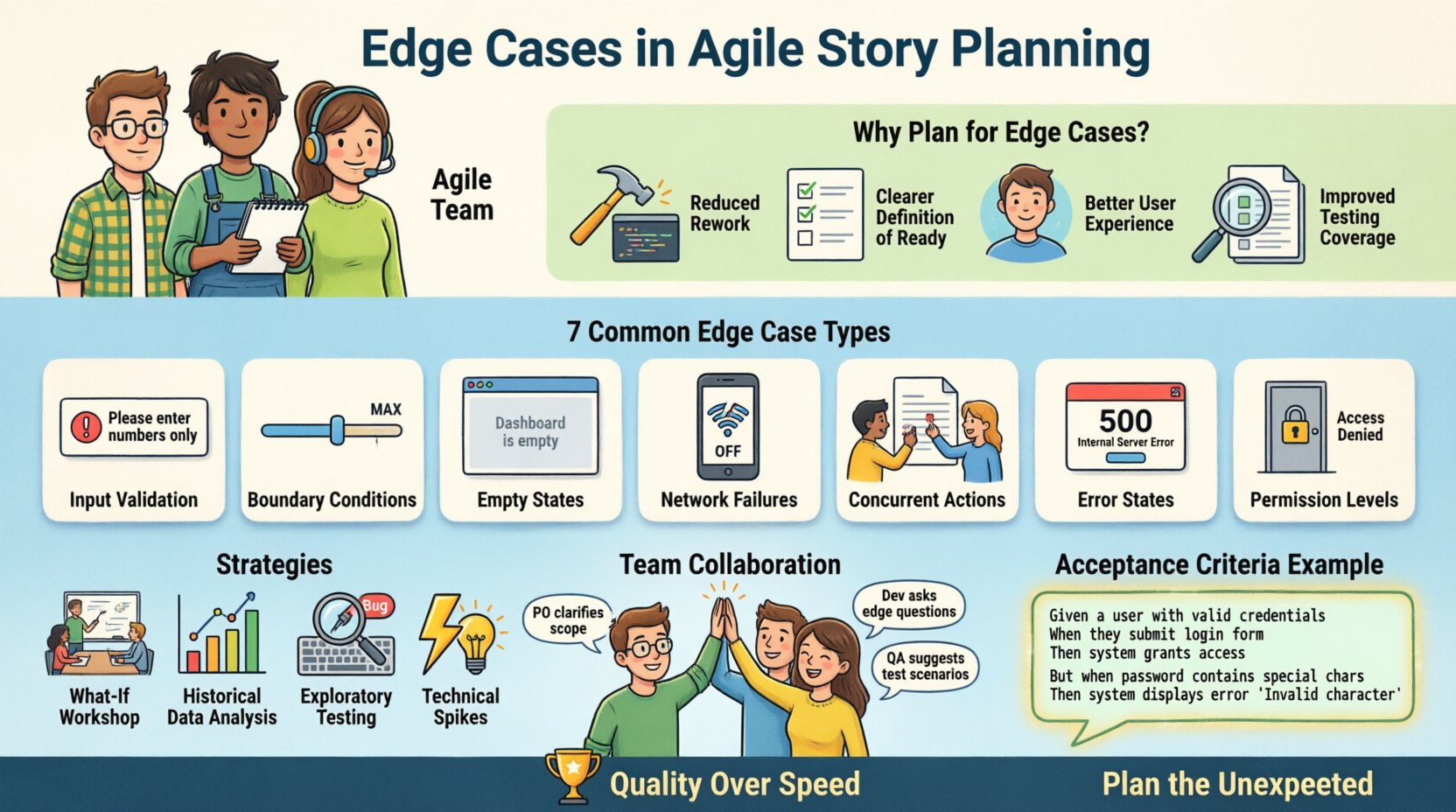
In der dynamischen Welt der Softwareentwicklung legen agile Methoden Wert darauf, schnell Nutzen zu liefern. Doch Geschwindigkeit ohne Präzision führt oft zu technischem Schuldenberg und Unzufriedenheit der Nutzer. Ein kritischer Bereich, in dem die Qualität häufig beeinträchtigt wird, ist die Planungsphase von Benutzerstories. Insbesondere das Übersehen von Randfällen kann dazu führen, dass Systeme unter idealen Bedingungen funktionieren, aber versagen, wenn reale Szenarien eintreten.
Randfälle sind Szenarien, die außerhalb des normalen, erwarteten Verhaltens eines Systems liegen. Sie repräsentieren oft die Grenzen der Funktionalität, Fehlerzustände oder seltene Bedingungen, mit denen Benutzer konfrontiert werden könnten. Wenn diese bei der Story-Planung ignoriert werden, steht das Entwicklungsteam vor Nacharbeit, verzögerten Releases und enttäuschten Stakeholdern.
Dieser Artikel untersucht, wie Randfälle innerhalb agiler Benutzerstories effektiv erkannt, geplant und verwaltet werden können. Wir betrachten praktische Strategien, Akzeptanzkriterien und Techniken zur Teamzusammenarbeit, die eine robuste Softwarebereitstellung ermöglichen, ohne den Arbeitsablauf zu verlangsamen.
🤔 Was sind Randfälle in Benutzerstories?
Ein Randfall ist ein Szenario, bei dem eine Benutzereingabe oder ein Systemzustand außerhalb des typischen Bereichs der Operation liegt. Im Kontext einer Benutzerstory sind dies die „Was wäre, wenn“-Fragen, die bei der ersten Formulierung der Akzeptanzkriterien oft vergessen werden.
Betrachten Sie eine Story über „Einloggen in ein System“. Der glückliche Pfad besteht darin, einen gültigen Benutzernamen und ein Passwort einzugeben, um auf das Dashboard zuzugreifen. Die Randfälle umfassen:
- Eingabe eines Benutzernamens mit Sonderzeichen.
- Eingabe eines Passworts, das zu kurz ist.
- Eingabe der korrekten Anmeldedaten, aber das Konto ist aufgrund zu vieler fehlgeschlagener Versuche gesperrt.
- Eingabe der Anmeldedaten, während offline.
- Eingabe eines leeren Benutzernamensfelds.
Wenn diese Szenarien bei der Planung nicht berücksichtigt werden, könnte der Entwickler den glücklichen Pfad implementieren und den Rest später behandeln. Dies führt zu „Spikes“ (zeitlich begrenzten Forschungsaufgaben), die den Sprint stören, oder schlimmer noch, zu Bugs, die in die Produktion gelangen.
🚨 Warum das Ignorieren von Randfällen die Geschwindigkeit beeinträchtigt
Viele Teams lassen Randfälle aus, um Zeit zu sparen. Sie glauben, diese später bearbeiten zu können, nachdem die Hauptfunktion erstellt wurde. Dieser Ansatz erzeugt oft eine Engstelle. Hier ist, warum die Planung von Randfällen entscheidend ist, um die Geschwindigkeit aufrechtzuerhalten:
- Verringerte Nacharbeit:Die frühzeitige Identifizierung von Einschränkungen verhindert Code, der neu geschrieben werden muss. Ein logischer Fehler im Entwurfsphase zu beheben, ist kostengünstiger als die Behebung im Produktivbetrieb.
- Klare Definition von „Ready“:Eine Story mit gut definierten Randfällen ist wirklich „bereit“ für die Entwicklung. Entwickler müssen während des Sprints nicht anhalten, um Klärungsfragen zu stellen.
- Verbesserte Testabdeckung:QA-Teams können umfassende Testfälle erstellen, wenn die Randfälle in der Story dokumentiert sind. Dies verringert die Anzahl der Fehlerberichte, die während des Sprints eingereicht werden.
- Bessere Benutzererfahrung:Benutzer kümmern sich nicht um den glücklichen Pfad. Sie interessieren sich dafür, was passiert, wenn Dinge schief laufen. Die geschickte Behandlung von Randfällen schafft Vertrauen.
📊 Häufige Arten von Randfällen, die geplant werden müssen
Um Teams zu helfen, sich daran zu erinnern, worauf sie achten müssen, ist es sinnvoll, Randfälle zu kategorisieren. Die folgende Tabelle zeigt gängige Kategorien und Beispiele, die für die allgemeine Softwareentwicklung relevant sind.
| Kategorie | Beschreibung | Beispiel-Szenario |
|---|---|---|
| Eingabeverifizierung | Behandlung von Daten, die außerhalb erwarteter Formate liegen. | Eingabe von Text in ein numerisches Feld. |
| Grenzbedingungen | Testen der Grenzen von Datumbereichen. | Maximale Zeichenanzahl in einem Textfeld. |
| Leerzustände | Wie das System aussieht, wenn keine Daten vorhanden sind. | Eine Dashboard ohne aktuelle Aktivität. |
| Netzwerkausfälle | Systemverhalten bei Verbindungsverlust. | Ein Formular senden, während offline. |
| Gleichzeitige Aktionen | Mehrere Benutzer oder Systeme, die gleichzeitig handeln. | Zwei Benutzer, die versuchen, dasselbe Datensatz zu bearbeiten. |
| Fehlerzustände | Umgang mit System- oder externen Dienstausfällen. | Die Zahlungsabwicklung gibt einen Timeout-Fehler zurück. |
| Berechtigungsebenen | Zugriffssteuerung für verschiedene Benutzerrollen. | Ein Standardbenutzer, der versucht, auf die Administratoreinstellungen zuzugreifen. |
Die Überprüfung dieser Liste während der Backlog-Refinement kann die Qualität der Geschichten erheblich verbessern.
🛠 Strategien zur Identifizierung von Randfällen
Die Identifizierung sollte keine zufällige Aktivität sein. Sie erfordert einen strukturierten Ansatz während der Planungssitzungen. Hier sind mehrere Techniken, um potenzielle Randfälle aufzudecken.
1. Der „Was wäre wenn“-Workshop
Während der Backlog-Refinement widmen Sie einem bestimmten Teil der Sitzung der Fragestellung „Was wäre wenn?“. Der Product Owner oder Moderator führt das Team durch die Benutzerreise und stoppt bei jedem Schritt, um zu fragen, was schiefgehen könnte.
- Was wäre, wenn der Benutzer den Browser während des Vorgangs schließt?
- Was wäre, wenn die Datenbank ausgefallen ist?
- Was wäre, wenn die Dateiübertragung größer ist, als der Server zulässt?
Das Aufschreiben dieser Antworten direkt in die Story-Notizen stellt sicher, dass sie nicht verloren gehen.
2. Überprüfung historischer Daten
Schauen Sie sich Fehlerberichte aus früheren Sprints an. Viele Randfälle sind wiederkehrende Probleme, die bereits in der Produktion aufgetreten sind. Wenn ein bestimmter Fehler letztes Monat aufgetreten ist, sollte er explizit in der aktuellen Story geplant werden.
3. Exploratives Testen
Bevor die Entwicklung beginnt, sollten die QA-Abteilung oder die Entwickler eine kurze Zeit damit verbringen, die Anwendung zu erkunden. Absichtliche Beschädigung der Anwendung kann Randfälle aufzeigen, die bei der Dokumentation nicht berücksichtigt wurden.
4. Technische Spikes
Für komplexe Funktionen kann ein technischer Spike notwendig sein. Dabei handelt es sich um eine zeitlich begrenzte Untersuchung, um die Durchführbarkeit der Behandlung bestimmter Randfälle zu verstehen. Die Ausgabe ist kein Code, sondern vielmehr eine Empfehlung, wie mit der Situation umzugehen ist.
📝 Schreiben von Akzeptanzkriterien für Randfälle
Akzeptanzkriterien sind die Bedingungen, die erfüllt sein müssen, damit eine Geschichte als abgeschlossen gilt. Sie bilden den Vertrag zwischen dem Team und dem Product Owner. Randfälle müssen hier enthalten sein.
Vermeiden Sie bei der Formulierung dieser Kriterien vage Formulierungen. Verwenden Sie konkrete Bedingungen.
- Schlecht: „Das System sollte Fehler behandeln.“
- Gut: „Wenn die API einen 500-Fehler zurückgibt, zeige eine generische Meldung ‚Etwas ist schiefgelaufen‘ an und versuche die Verbindung nach 5 Sekunden erneut herzustellen.“
Die Verwendung von BDD-Syntax, wie beispielsweise Gherkin, kann ebenfalls helfen, diese Kriterien klar zu strukturieren.
Beispiel: Gherkin-Syntax für Randfälle
Gegeben ist, dass der Benutzer auf der Checkout-Seite ist Und der Zahlungsgateway nicht erreichbar ist Wenn der Benutzer auf ‚Jetzt bezahlen‘ klickt Dann sollte das System einen Fehler ‚Dienst nicht verfügbar‘ anzeigen Und dem Benutzer erlauben, die Aktion erneut zu versuchen oder abzubrechen
Dieses Format zwingt das Team dazu, über die Voraussetzungen (Gegeben), die Aktion (Wenn) und das Ergebnis (Dann), einschließlich Fehlerzustände, nachzudenken.
🛡 Die Definition von Bereitschaft (DoR)
Die Definition von Bereitschaft ist eine Prüfliste mit Kriterien, die eine Benutzerstory erfüllen muss, bevor sie in einen Sprint eintritt. Die Einbeziehung von Randfällen in die DoR stellt sicher, dass Geschichten nicht ohne ausreichende Planung in die Entwicklung übernommen werden.
Eine robuste DoR zur Behandlung von Randfällen könnte Folgendes enthalten:
- Sind die normalen Abläufe eindeutig definiert?
- Sind alle wichtigen Fehlerzustände identifiziert worden?
- Gibt es Akzeptanzkriterien für leere Zustände?
- Wurde die Auswirkung auf bestehende Daten analysiert?
- Hat das Sicherheitsteam die Zugriffssteuerungen überprüft?
Wenn eine Geschichte diese Kriterien nicht erfüllen kann, sollte sie im Backlog verbleiben. Das Einziehen trotzdem birgt das Risiko unvollständiger Arbeit.
🤝 Zusammenarbeit über Rollen hinweg
Die Identifizierung von Randfällen ist nicht allein die Aufgabe der Entwickler. Es erfordert die Zusammenarbeit des gesamten Produktteams.
Product Owner
Product Owner verstehen den geschäftlichen Wert und den Nutzerkontext. Sie sind am besten dafür geeignet, Szenarien zu identifizieren, die die Geschäftslogik brechen. Zum Beispiel könnte ein Benutzer versuchen, ein Produkt zu kaufen, wenn seine Kreditkarte abgelaufen ist. Dies ist ein geschäftlicher Randfall.
Entwickler
Entwickler verstehen die Systemarchitektur. Sie wissen, wo das System anfällig ist. Sie können technische Randfälle identifizieren, wie beispielsweise Rennbedingungen oder Speicherbegrenzungen.
Qualitätssicherung
QA-Ingenieure werden darauf trainiert, Dinge zu zerstören. Sie sollten die User Stories vor Beginn des Sprints überprüfen, um sicherzustellen, dass die Randfälle testbar sind. Wenn ein Szenario nicht getestet werden kann, ist es nicht ausreichend definiert.
⚙️ Umgang mit technischem Schulden aus Randfällen
Manchmal erfordert die Behandlung eines Randfalls eine erhebliche Menge an Arbeit, die den Fluss von Funktionen stört. Dies kann zu technischem Schulden führen. Es ist wichtig, dieses Gleichgewicht zu managen.
- Priorisieren nach Risiko: Nicht alle Randfälle sind gleich. Ein Login-Fehler ist von hohem Risiko. Ein geringfügiger Formatierungsfehler in einem selten genutzten Bericht ist von geringem Risiko. Priorisieren Sie nach Auswirkung.
- Verschieben mit einem Plan: Wenn ein Randfall mit geringem Risiko derzeit nicht behandelt werden kann, dokumentieren Sie ihn. Fügen Sie ihn einer Liste „Bekannte Probleme“ hinzu und planen Sie ihn für einen zukünftigen technischen Spikes.
- Regelmäßig refaktorisieren: Widmen Sie einen Teil jedes Sprints der Refaktorisierung. Dadurch verhindern Sie, dass die Behandlung von Randfällen zu einem riesigen, unerhaltbaren Codeblock wird.
📈 Metriken für kontinuierliche Verbesserung
Um sicherzustellen, dass der Planungsprozess sich verbessert, verfolgen Sie spezifische Metriken im Zusammenhang mit Randfällen.
- Fehler-Entweichungsrate: Wie viele Fehler im Zusammenhang mit Randfällen werden in der Produktion gefunden? Eine hohe Rate deutet darauf hin, dass die Planung unzureichend ist.
- Story-Umarbeitung: Wie oft kehren Stories aufgrund fehlender Akzeptanzkriterien in das Backlog zurück?
- QA-Bestehensrate: Welcher Prozentsatz der Testfälle besteht beim ersten Versuch? Eine niedrige Bestehensrate deutet auf unklare Anforderungen hin.
Die Überprüfung dieser Metriken in Retrospektiven kann dem Team helfen, ihre Planungsgewohnheiten anzupassen.
🧭 Kultureller Wandel: Qualität vor Geschwindigkeit
Schließlich ist der wichtigste Faktor die Kultur. Wenn das Team unter Druck steht, alles zu liefern, werden Randfälle ignoriert. Die Führung muss betonen, dass Qualität eine Funktion ist, keine Nachbereitung.
Wenn ein Teammitglied einen Randfall identifiziert, der eine Freigabe verzögert, sollte es dafür belohnt werden, nicht bestraft. Dies fördert proaktive Planung und verringert die Angst vor Verzögerungen.
🔄 Refinement ist kontinuierlich
Die Identifizierung von Randfällen ist kein einmaliger Vorgang. Während die Anwendung sich weiterentwickelt, entstehen neue Randfälle. Regelmäßige Backlog-Refinement-Sitzungen sollten ältere Stories erneut prüfen, um festzustellen, ob neue Szenarien hinzugefügt werden müssen.
Zum Beispiel könnte eine neue Integration mit einem Drittanbieter-Service neue Netzwerk-Latenzprobleme verursachen, die in bestehenden Stories berücksichtigt werden müssen. Kontinuierliche Refinement hält das Backlog aktuell und das System robust.
✅ Zusammenfassung
Die Planung für Randfälle ist eine grundlegende Disziplin im agilen Softwareentwicklung. Sie erfordert Aufwand zu Beginn, zahlt sich aber in Form von reduziertem Nacharbeit, besseren Benutzererfahrungen und stabilen Systemen aus. Durch den Einsatz strukturierter Techniken wie „Was wäre wenn“-Workshops, klaren Akzeptanzkriterien und einer robusten Definition von „Ready“ können Teams die Komplexität effektiv managen.
Denken Sie daran, dass Geschwindigkeit ohne Qualität eine Illusion ist. Die Investition von Zeit in die Planung für das Unerwartete stellt sicher, dass das Team kontinuierlich und zuverlässig Wert liefern kann. Jede Story ist eine Gelegenheit, ein widerstandsfähigeres Produkt zu bauen.
Beginnen Sie klein. Wählen Sie eine anstehende Story aus und überprüfen Sie ihre Randfälle. Fordern Sie das Team auf, den „glücklichen Pfad“ herauszufordern. Sie werden wahrscheinlich Möglichkeiten finden, die Qualität der Arbeit zu verbessern, bevor überhaupt ein einziger Codezeile geschrieben wurde.

