










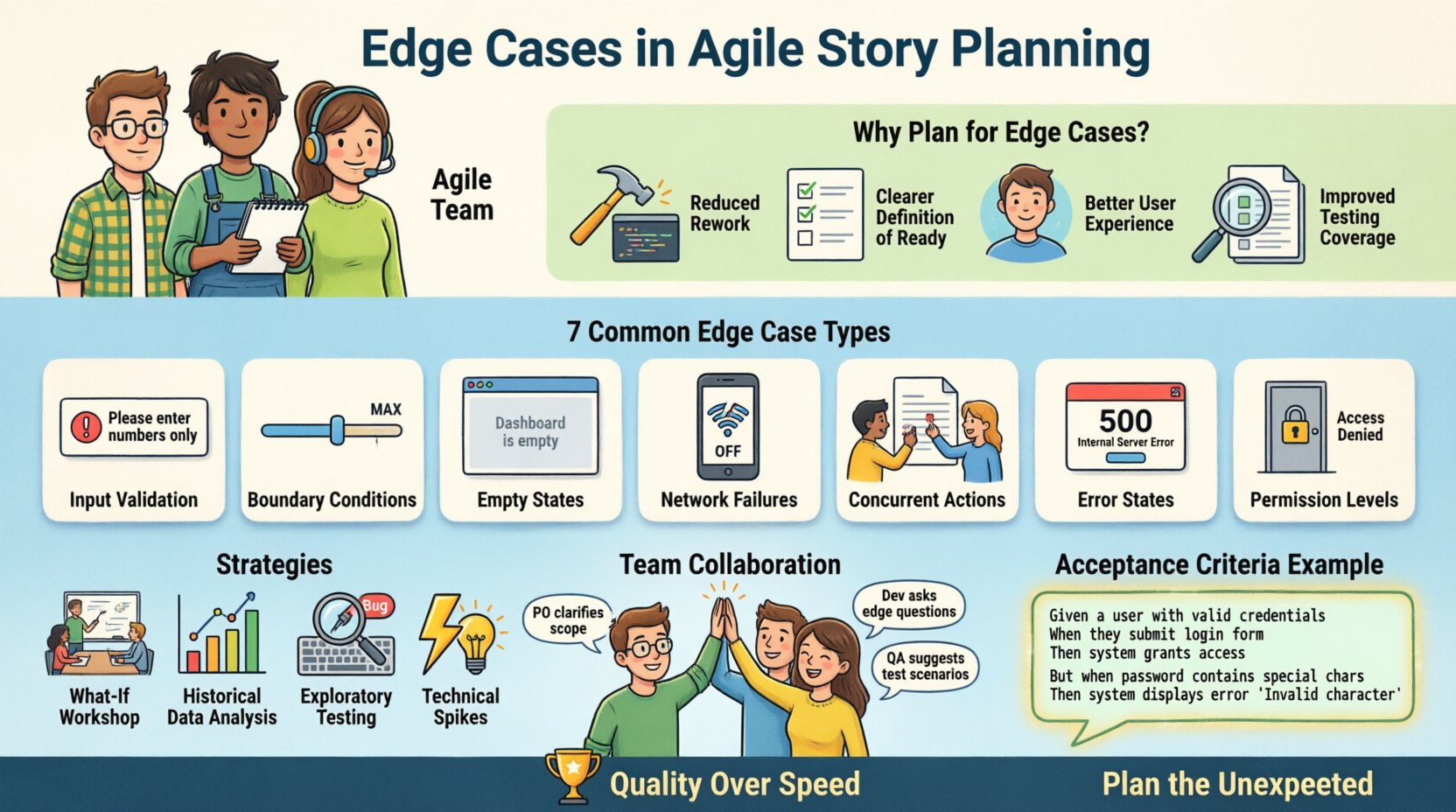
W szybko zmieniającym się świecie rozwoju oprogramowania metodyki Agile skupiają się na szybkim dostarczaniu wartości. Jednak szybkość bez precyzji często prowadzi do długu technicznego i niezadowolenia użytkowników. Jednym z kluczowych obszarów, w którym jakość często jest kompromitowana, jest faza planowania historii użytkownika. W szczególności pomijanie przypadków krawędziowych może prowadzić do systemów, które działają w idealnych warunkach, ale zawodzą, gdy pojawiają się rzeczywiste scenariusze.
Przypadki krawędziowe to scenariusze, które wypadają poza normalnym, oczekiwanym zachowaniem systemu. Często reprezentują granice funkcjonalności, stany błędów lub rzadkie sytuacje, z którymi użytkownicy mogą się zetknąć. Gdy są one pomijane podczas planowania historii, zespół programistów staje przed ponowną pracą, opóźnionymi wersjami i frustracją klientów.
Ten artykuł omawia, jak skutecznie identyfikować, planować i zarządzać przypadkami krawędziowymi w historiach użytkownika Agile. Przyjrzymy się praktycznym strategiom, kryteriom akceptacji oraz technikom współpracy zespołu, które zapewniają solidne dostarczanie oprogramowania bez spowolnienia przepływu pracy.
🤔 Co to są przypadki krawędziowe w historiach użytkownika?
Przypadek krawędziowy to sytuacja, w której dane wejściowe użytkownika lub stan systemu wypadają poza typowym zakresem działania. W kontekście historii użytkownika są to pytania typu „co jeśli”, które często są pomijane podczas pierwszego przygotowywania kryteriów akceptacji.
Rozważmy historię dotyczącą „Logowania się do systemu”. Scenariusz główny to wpisanie poprawnej nazwy użytkownika i hasła w celu uzyskania dostępu do pulpitu. Przypadki krawędziowe obejmują:
- Wprowadzenie nazwy użytkownika z znakami specjalnymi.
- Wprowadzenie hasła, które jest zbyt krótkie.
- Wprowadzenie poprawnych danych logowania, ale zablokowanie konta z powodu zbyt wielu nieudanych prób.
- Wprowadzenie danych logowania w trybie offline.
- Wprowadzenie pustego pola nazwy użytkownika.
Jeśli te scenariusze nie zostaną rozważone podczas planowania, programista może zaimplementować tylko główny przypadek i odłożyć resztę na później. Może to prowadzić do „spików” (zadań badawczych z czasem ograniczonym), które przerywają sprint, albo jeszcze gorzej — do błędów trafiających do produkcji.
🚨 Dlaczego pomijanie przypadków krawędziowych szkodzi prędkości pracy
Wiele zespołów pomija przypadki krawędziowe, aby oszczędzić czas. Wierzą, że mogą je rozwiązać później, po zbudowaniu głównej funkcji. Ten podejście często tworzy zatory. Oto dlaczego planowanie przypadków krawędziowych jest kluczowe dla utrzymania prędkości pracy:
- Zmniejszona ilość ponownej pracy:Wczesne identyfikowanie ograniczeń zapobiega tworzeniu kodu, który będzie musiał zostać przepisany. Naprawienie błędu logicznego w fazie projektowania jest tańsze niż naprawa go w produkcji.
- Jasniejsze określenie gotowości:Historia z dobrze zdefiniowanymi przypadkami krawędziowymi jest naprawdę „gotowa” do realizacji. Programiści nie muszą zatrzymywać się i zadawać pytań wyjaśniających w trakcie sprintu.
- Poprawiona pokrycie testów:Zespoły QA mogą tworzyć kompleksowe przypadki testowe, jeśli przypadki krawędziowe są zapisane w historii. To zmniejsza liczbę zgłoszeń błędów w trakcie sprintu.
- Lepsze doświadczenie użytkownika:Użytkownicy nie dbają o główny przypadek. Dbają o to, co się dzieje, gdy coś poszło nie tak. Zdrowe radzenie sobie z przypadkami krawędziowymi buduje zaufanie.
📊 Powszechne typy przypadków krawędziowych do zaplanowania
Aby pomóc zespołom pamiętać, na co zwracać uwagę, przydatne jest kategoryzowanie przypadków krawędziowych. Poniższa tabela przedstawia typowe kategorie oraz przykłady istotne dla ogólnego rozwoju oprogramowania.
| Kategoria | Opis | Przykładowy scenariusz |
|---|---|---|
| Weryfikacja danych wejściowych | Obsługa danych, które wypadają poza oczekiwanymi formatami. | Wprowadzanie tekstu do pola numerycznego. |
| Warunki graniczne | Testowanie granic zakresów danych. | Maksymalna liczba znaków w polu tekstowym. |
| Stany puste | Jak wygląda system, gdy nie ma danych. | Pulpit bez ostatniej aktywności. |
| Awarie sieci | Zachowanie systemu podczas utraty połączenia. | Przesyłanie formularza w trybie offline. |
| Działania współbieżne | Wiele użytkowników lub systemów działających jednocześnie. | Dwóch użytkowników próbujących edytować ten sam rekord. |
| Stany błędów | Obsługa awarii systemu lub zewnętrznych usług. | Brama płatności zwraca błąd przekroczenia czasu. |
| Poziomy uprawnień | Kontrola dostępu dla różnych ról użytkowników. | Użytkownik standardowy próbujący uzyskać dostęp do ustawień administratora. |
Przeglądanie tej listy podczas dopasowania backlogu może znacząco poprawić jakość historii.
🛠 Strategie identyfikowania przypadków brzegowych
Identyfikacja nie powinna być przypadkową czynnością. Wymaga ona strukturalnego podejścia podczas sesji planowania. Oto kilka technik ujawniających potencjalne przypadki brzegowe.
1. Warsztat „A co jeśli?“
Podczas dopasowania backlogu poświęć określoną część sesji na zadawanie pytania „A co jeśli?“. Właściciel produktu lub prowadzący prowadzi zespół przez przebieg użytkownika i zatrzymuje się na każdym kroku, by zadać pytanie, co może pójść nie tak.
- A co jeśli użytkownik zamknie przeglądarkę w trakcie procesu?
- A co jeśli baza danych jest niedostępna?
- A co jeśli przesyłany plik jest większy niż dozwolone przez serwer?
Zapisywanie tych odpowiedzi bezpośrednio w notatkach do historii zapewnia, że nie zostaną utracone.
2. Przeglądanie danych historycznych
Spójrz na raporty błędów z poprzednich sprintów. Wiele przypadków brzegowych to powtarzające się problemy, które pojawiły się w środowisku produkcyjnym. Jeśli konkretny błąd pojawił się w zeszłym miesiącu, powinien być jawnie zaplanowany w bieżącej historii.
3. Testy eksploracyjne
Zanim zacznie się rozwój, niech zespół QA lub deweloperzy poświęcą krótki czas na eksplorację aplikacji. Celowe uszkodzenie aplikacji może ujawnić przypadki graniczne, które nie zostały rozważone podczas dokumentacji.
4. Spiky techniczne
Dla złożonych funkcjonalności może być konieczny spik techniczny. Jest to ograniczona czasowo analiza, mająca na celu zrozumienie możliwości obsługi konkretnych przypadków granicznych. Wynikiem nie jest kod, lecz raczej rekomendacja dotycząca sposobu obsługi danego scenariusza.
📝 Tworzenie kryteriów akceptacji dla przypadków granicznych
Kryteria akceptacji to warunki, które muszą zostać spełnione, aby historia mogła być uznana za zakończoną. Są one umową między zespołem a właścicielem produktu. Przypadki graniczne muszą być tu uwzględnione.
Podczas pisania tych kryteriów unikaj nieprecyzyjnego języka. Używaj konkretnych warunków.
- Zły: „System powinien obsługiwać błędy.”
- Dobry: „Jeśli API zwraca błąd 500, wyświetl ogólny komunikat „Coś poszło nie tak” i ponów połączenie po 5 sekundach.”
Używanie składni zgodnej z rozwojem opartym na zachowaniach (BDD), takiej jak Gherkin, może również pomóc w jasnym sformułowaniu tych kryteriów.
Przykład: składnia Gherkin dla przypadków granicznych
Dane: użytkownik znajduje się na stronie zakupów I bramka płatności jest niedostępna Kiedy użytkownik kliknie „Zapłać teraz” To system powinien wyświetlić błąd „Usługa niedostępna” I pozwolić użytkownikowi na ponowną próbę lub anulowanie
Ten format zmusza zespół do rozważenia warunków wstępnych (Dane), działania (Kiedy) oraz wyniku (To), w tym stanów błędów.
🛡 Definicja gotowości (DoR)
Definicja gotowości to lista kryteriów, które historia użytkownika musi spełnić, zanim wejdzie do sprintu. Włączenie przypadków granicznych do Definicji Gotowości zapewnia, że historie nie będą wciągane do rozwoju bez odpowiedniego planowania.
Solidna Definicja Gotowości do obsługi przypadków granicznych może obejmować:
- Czy ścieżki główne są jasno zdefiniowane?
- Czy wszystkie główne stany błędów zostały zidentyfikowane?
- Czy istnieją kryteria akceptacji dla stanów pustych?
- Czy wpływ na istniejące dane został przeanalizowany?
- Czy zespół bezpieczeństwa przeanalizował kontrole dostępu?
Jeśli historia nie może spełnić tych kryteriów, powinna pozostać w kolejce. Wciąganie jej mimo to stwarza ryzyko nieukończonej pracy.
🤝 Współpraca między rolami
Identyfikacja przypadków granicznych nie jest wyłącznie obowiązkiem deweloperów. Wymaga współpracy całego zespołu produktu.
Właściciele produktu
Właściciele produktu rozumieją wartość biznesową i kontekst użytkownika. Są najlepiej przygotowani do identyfikacji scenariuszy, które naruszają logikę biznesową. Na przykład użytkownik może spróbować kupić przedmiot, gdy jego karta kredytowa wygasła. Jest to przypadek graniczny biznesowy.
Deweloperzy
Deweloperzy rozumieją architekturę systemu. Wiedzą, gdzie system jest wrażliwy. Mogą identyfikować przypadki graniczne techniczne, takie jak warunki wyścigu lub limity pamięci.
Zapewnienie jakości
Inżynierowie QA są szkoleni, aby łamać rzeczy. Powinni przejrzeć historie użytkownika przed rozpoczęciem sprintu, aby upewnić się, że przypadki krawędziowe są testowalne. Jeśli scenariusz nie może być przetestowany, nie jest wystarczająco dobrze zdefiniowany.
⚙️ Obsługa długu technicznego wynikającego z przypadków krawędziowych
Czasem obsługa przypadku krawędziowego wymaga znacznej ilości pracy, która zakłóca przepływ funkcji. Może to prowadzić do długu technicznego. Ważne jest zarządzanie tym równowagą.
- Priorytet na podstawie ryzyka:Nie wszystkie przypadki krawędziowe są równe. Awaria logowania to wysokie ryzyko. Mały problem z formatowaniem w rzadko używanym raporcie to niskie ryzyko. Priorytetuj na podstawie skutku.
- Odwlecz z planem: Jeśli przypadku krawędziowego o niskim ryzyku nie można teraz obsłużyć, zarejestruj go. Dodaj go do listy „Znane problemy” i zaplanuj jego rozwiązanie w przyszłym technicznym spike.
- Regularnie przepisuj kod: Przypisz część każdego sprintu do przepisywania kodu. Zapobiega to temu, by obsługa przypadków krawędziowych stała się ogromnym, nieobsługiwalnym blokiem kodu.
📈 Metryki do ciągłego doskonalenia
Aby upewnić się, że proces planowania się poprawia, śledź konkretne metryki związane z przypadkami krawędziowymi.
- Wskaźnik ucieczki błędów: Ile błędów związanych z przypadkami krawędziowymi znajduje się w środowisku produkcyjnym? Wysoki wskaźnik sugeruje, że planowanie jest niewystarczające.
- Przerobienie historii: Jak często historie powracają do backlogu z powodu braku kryteriów akceptacji?
- Wskaźnik ukończenia testów QA: Jaki procent przypadków testowych zalicza się za pierwszym razem? Niski wskaźnik wskazuje na niejasne wymagania.
Przeglądanie tych metryk w retrospektywach może pomóc zespołowi dostosować swoje nawyki planowania.
🧭 Przesunięcie kulturowe: jakość przede wszystkim
Na końcu najważniejszym czynnikiem jest kultura. Jeśli zespół czuje presję, by wysłać produkt za wszelką cenę, przypadki krawędziowe zostaną zignorowane. Liderzy muszą podkreślać, że jakość to cecha, a nie pożądane dodatkowe działanie.
Gdy członek zespołu wykryje przypadek krawędziowy, który opóźnia wypuszczenie, powinien być nagradzany za jego wykrycie, a nie karany. To zachęca do proaktywnej pracy i zmniejsza obawy przed spowolnieniem.
🔄 Doskonalenie jest ciągłe
Identyfikacja przypadków krawędziowych to nie jednorazowy wydarzenie. W miarę rozwoju aplikacji pojawiają się nowe przypadki krawędziowe. Regularne sesje doskonalenia backlogu powinny ponownie przeglądać starsze historie, aby sprawdzić, czy potrzebne są dodatkowe scenariusze.
Na przykład nowa integracja z usługą zewnętrznej może wprowadzić nowe problemy z opóźnieniem sieciowym, które należy rozwiązać w istniejących historiach. Ciągłe doskonalenie utrzymuje backlog aktualny i system odporny.
✅ Podsumowanie
Planowanie przypadków krawędziowych to podstawowa dyscyplina w rozwoju oprogramowania Agile. Wymaga to wysiłku na początku, ale przynosi korzyści w postaci zmniejszonej ilości ponownej pracy, lepszych doświadczeń użytkowników i stabilnych systemów. Dzięki strukturalnym technikom, takim jak warsztaty „A co jeśli”, jasnym kryteriom akceptacji i solidnej definicji gotowości, zespoły mogą skutecznie zarządzać złożonością.
Pamiętaj, że szybkość bez jakości to iluzja. Inwestowanie czasu w planowanie nieprzewidywalnych sytuacji zapewnia, że zespół może ciągle i wiarygodnie dostarczać wartość. Każda historia to okazja, by stworzyć bardziej odporny produkt.
Zacznij od małego. Wybierz jedną nadchodząca historię i przeanalizuj jej przypadki krawędziowe. Poproś zespół, by wyzwała drogę szczęścia. Z dużym prawdopodobieństwem znajdziesz możliwości poprawy jakości pracy, zanim zostanie napisany pierwszy wiersz kodu.

