










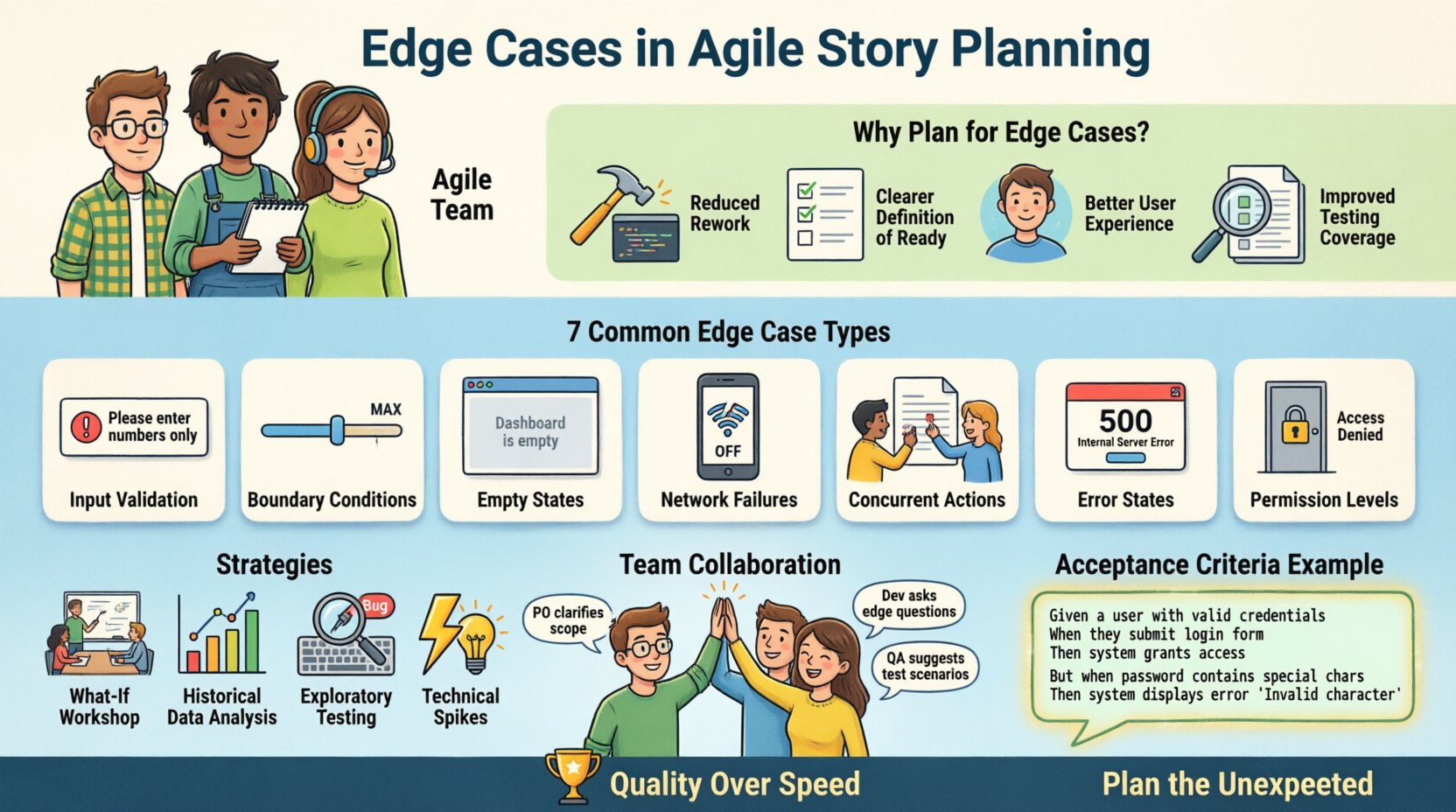
En el mundo acelerado del desarrollo de software, las metodologías Ágiles priorizan entregar valor rápidamente. Sin embargo, la velocidad sin precisión a menudo conduce a deuda técnica y insatisfacción del usuario. Una de las áreas críticas donde la calidad con frecuencia se compromete es la fase de planificación de las historias de usuario. Específicamente, ignorar los casos de borde puede resultar en sistemas que funcionan bajo condiciones perfectas pero fallan cuando ocurren escenarios del mundo real.
Los casos de borde son escenarios que caen fuera del comportamiento normal y esperado de un sistema. A menudo representan los límites de la funcionalidad, estados de error o condiciones raras que los usuarios podrían encontrar. Cuando estos casos se ignoran durante la planificación de historias, el equipo de desarrollo enfrenta rehacer trabajo, lanzamientos retrasados y stakeholders frustrados.
Este artículo explora cómo identificar, planificar y gestionar eficazmente los casos de borde dentro de las historias de usuario ágiles. Examinaremos estrategias prácticas, criterios de aceptación y técnicas de colaboración entre equipos que garantizan una entrega de software robusta sin ralentizar el flujo de trabajo.
🤔 ¿Qué son los casos de borde en las historias de usuario?
Un caso de borde es un escenario en el que una entrada del usuario o un estado del sistema cae fuera del rango típico de operación. En el contexto de una historia de usuario, estos son las preguntas del tipo «¿y si?» que con frecuencia se olvidan durante la redacción inicial de los criterios de aceptación.
Considere una historia sobre «Iniciar sesión en un sistema». El camino feliz consiste en ingresar un nombre de usuario y contraseña válidos para acceder al panel de control. Los casos de borde incluyen:
- Ingresar un nombre de usuario con caracteres especiales.
- Ingresar una contraseña que sea demasiado corta.
- Ingresar las credenciales correctas pero tener la cuenta bloqueada debido a demasiados intentos fallidos.
- Ingresar credenciales mientras se está desconectado.
- Ingresar un campo de nombre de usuario vacío.
Si estos escenarios no se abordan durante la planificación, el desarrollador podría implementar solo el camino feliz y dejar lo demás para más adelante. Esto conduce a «spikes» (tareas de investigación con tiempo limitado) que interrumpen la iteración, o peor aún, a errores que llegan a producción.
🚨 ¿Por qué ignorar los casos de borde afecta la velocidad?
Muchos equipos omiten los casos de borde para ahorrar tiempo. Creen que pueden abordarlos después de construir la funcionalidad principal. Este enfoque a menudo crea un cuello de botella. Estas son las razones por las que planificar los casos de borde es esencial para mantener la velocidad:
- Reducción de rehacer trabajo:Identificar las restricciones temprano evita código que necesite ser reescrito. Corregir un error lógico en la fase de diseño es más económico que corregirlo en producción.
- Definición más clara de listo:Una historia con casos de borde bien definidos está verdaderamente «lista» para el desarrollo. Los desarrolladores no necesitan detenerse y hacer preguntas de aclaración durante la iteración.
- Mejor cobertura de pruebas:Los equipos de QA pueden crear casos de prueba completos si los casos de borde se documentan en la historia. Esto reduce el número de informes de errores presentados durante la iteración.
- Mejor experiencia del usuario:Los usuarios no se preocupan por el camino feliz. Se preocupan por lo que sucede cuando las cosas salen mal. Manejar los casos de borde con elegancia genera confianza.
📊 Tipos comunes de casos de borde para planificar
Para ayudar a los equipos a recordar qué buscar, es útil categorizar los casos de borde. La siguiente tabla presenta categorías comunes y ejemplos relevantes para el desarrollo general de software.
| Categoría | Descripción | Escenario de ejemplo |
|---|---|---|
| Validación de entrada | Manejar datos que están fuera de los formatos esperados. | Ingresar texto en un campo numérico. |
| Condiciones de borde | Probando los límites de los rangos de datos. | Límite máximo de caracteres en un cuadro de texto. |
| Estados vacíos | Cómo se ve el sistema cuando no existe ningún dato. | Un panel de control sin actividad reciente. |
| Fallos de red | Comportamiento del sistema durante la pérdida de conectividad. | Enviar un formulario mientras estás desconectado. |
| Acciones concurrentes | Varios usuarios o sistemas actuando al mismo tiempo. | Dos usuarios intentando editar el mismo registro. |
| Estados de error | Manejo de fallos del sistema o de servicios externos. | La pasarela de pagos devuelve un error de tiempo de espera. |
| Niveles de permisos | Control de acceso para diferentes roles de usuario. | Un usuario estándar intentando acceder a la configuración de administrador. |
Revisar esta lista durante la refinación del backlog puede mejorar significativamente la calidad de las historias.
🛠 Estrategias para identificar casos límite
La identificación no debe ser una actividad aleatoria. Requiere un enfoque estructurado durante las sesiones de planificación. Aquí hay varias técnicas para descubrir posibles casos límite.
1. El taller de «¿Y si?»
Durante la refinación del backlog, dedique una parte específica de la sesión a preguntar «¿Y si?». El propietario del producto o el facilitador guía al equipo a través del recorrido del usuario y se detiene en cada paso para preguntar qué podría salir mal.
- ¿Y si el usuario cierra el navegador durante el proceso?
- ¿Y si la base de datos está caída?
- ¿Y si la carga del archivo es mayor que la permitida por el servidor?
Registrar estas respuestas directamente en las notas de la historia asegura que no se pierdan.
2. Revisión de datos históricos
Revise los informes de errores de sprints anteriores. Muchos casos límite son problemas recurrentes que han aparecido en producción. Si un error específico ocurrió el mes pasado, debería planificarse explícitamente en la historia actual.
3. Pruebas exploratorias
Antes de comenzar el desarrollo, haz que el equipo de QA o los desarrolladores dediquen un breve tiempo a explorar la aplicación. Romper intencionalmente la aplicación puede revelar casos límite que no se consideraron durante la documentación.
4. Picos técnicos
Para características complejas, puede ser necesario un pico técnico. Se trata de una investigación con tiempo limitado para comprender la viabilidad de manejar casos límite específicos. El resultado no es código, sino más bien una recomendación sobre cómo abordar la situación.
📝 Escritura de criterios de aceptación para casos límite
Los criterios de aceptación son las condiciones que deben cumplirse para considerar que una historia está completa. Son el contrato entre el equipo y el propietario del producto. Aquí deben incluirse los casos límite.
Al escribir estos criterios, evita un lenguaje vago. Usa condiciones específicas.
- Malo: “El sistema debe manejar errores.”
- Bueno: “Si la API devuelve un error 500, muestra un mensaje genérico ‘Algo salió mal’ y vuelve a intentar la conexión después de 5 segundos.”
Utilizar la sintaxis de Desarrollo Dirigido por el Comportamiento (BDD), como Gherkin, también puede ayudar a estructurar estos criterios de forma clara.
Ejemplo: Sintaxis de Gherkin para casos límite
Dado que el usuario está en la página de pago Y la pasarela de pago no está disponible Cuando el usuario hace clic en "Pagar ahora" Entonces el sistema debe mostrar un error "Servicio no disponible" Y permitir al usuario reintentar o cancelar
Esta estructura obliga al equipo a pensar en las condiciones previas (Dado), la acción (Cuando) y el resultado (Entonces), incluyendo los estados de error.
🛡 La Definición de Listo (DoR)
La Definición de Listo es una lista de verificación de criterios que una historia de usuario debe cumplir antes de entrar en una iteración. Incluir casos límite en la DoR asegura que las historias no se pasen al desarrollo sin una planificación adecuada.
Una DoR sólida para manejar casos límite podría incluir:
- ¿Están claramente definidos los caminos principales?
- ¿Se han identificado todos los estados de error principales?
- ¿Existen criterios de aceptación para estados vacíos?
- ¿Se ha analizado el impacto sobre los datos existentes?
- ¿Ha revisado el equipo de seguridad los controles de acceso?
Si una historia no puede cumplir estos criterios, debe permanecer en el backlog. Incluirla de todos modos crea un riesgo de trabajo incompleto.
🤝 Colaboración entre roles
Identificar casos límite no es solo responsabilidad de los desarrolladores. Requiere colaboración entre todo el equipo de producto.
Propietarios de producto
Los propietarios de producto entienden el valor del negocio y el contexto del usuario. Están mejor posicionados para identificar escenarios que rompen la lógica del negocio. Por ejemplo, un usuario podría intentar comprar un artículo cuando su tarjeta de crédito ha caducado. Este es un caso límite de negocio.
Desarrolladores
Los desarrolladores entienden la arquitectura del sistema. Saben dónde el sistema es frágil. Pueden identificar casos límite técnicos, como condiciones de carrera o límites de memoria.
Garantía de calidad
Los ingenieros de QA están capacitados para romper cosas. Deben revisar las historias de usuario antes de que comience el sprint para asegurarse de que los casos límite sean testables. Si una situación no puede ser probada, no está definida lo suficientemente bien.
⚙️ Manejo de la deuda técnica derivada de casos límite
A veces, manejar un caso límite requiere una cantidad significativa de trabajo que interrumpe el flujo de las características. Esto puede generar deuda técnica. Es importante gestionar este equilibrio.
- Priorice por riesgo:No todos los casos límite son iguales. Un fallo en el inicio de sesión es de alto riesgo. Un problema menor de formato en un informe poco utilizado es de bajo riesgo. Priorice según el impacto.
- Diferir con un plan:Si un caso límite de bajo riesgo no puede manejarse ahora, documentélo. Agréguelo a una lista de “Problemas conocidos” y programelo para una futura sesión técnica.
- Refactore regularmente:Dedique una parte de cada sprint a la refactorización. Esto evita que el manejo de casos límite se convierta en un bloque masivo e inmantenible de código.
📈 Métricas para la mejora continua
Para asegurarse de que el proceso de planificación está mejorando, rastree métricas específicas relacionadas con los casos límite.
- Tasa de escape de errores:¿Cuántos errores relacionados con casos límite se encuentran en producción? Una tasa alta sugiere que la planificación es insuficiente.
- Rehacer historias:¿Con qué frecuencia las historias regresan al backlog debido a criterios de aceptación faltantes?
- Tasa de aprobación de QA:¿Qué porcentaje de casos de prueba aprueban en la primera ejecución? Una baja tasa de aprobación indica requisitos poco claros.
Revisar estas métricas en retrospectivas puede ayudar al equipo a ajustar sus hábitos de planificación.
🧭 Cambio cultural: Calidad sobre velocidad
Finalmente, el factor más importante es la cultura. Si el equipo siente presión por entregar a cualquier costo, los casos límite serán ignorados. La dirección debe reforzar que la calidad es una característica, no una consideración posterior.
Cuando un miembro del equipo identifica un caso límite que retrasa una liberación, debería ser recompensado por detectarlo, no sancionado. Esto fomenta la planificación proactiva y reduce el miedo a ralentizar el proceso.
🔄 La refinación es continua
La identificación de casos límite no es un evento único. A medida que la aplicación evoluciona, surgen nuevos casos límite. Las sesiones regulares de refinación del backlog deben revisar historias antiguas para ver si se necesitan agregar nuevos escenarios.
Por ejemplo, una nueva integración con un servicio de terceros podría introducir nuevos problemas de latencia de red que necesitan ser manejados en historias existentes. La refinación continua mantiene el backlog actualizado y el sistema robusto.
✅ Resumen
Planificar los casos límite es una disciplina fundamental en el desarrollo de software ágil. Requiere esfuerzo desde el inicio, pero genera beneficios en la reducción de rehacer trabajo, mejores experiencias de usuario y sistemas estables. Al utilizar técnicas estructuradas como talleres de “¿Y si?”, criterios de aceptación claros y una Definición de Listo sólida, los equipos pueden gestionar la complejidad de forma efectiva.
Recuerde que la velocidad sin calidad es una ilusión. Invertir tiempo en planificar lo inesperado garantiza que el equipo pueda entregar valor de forma consistente y confiable. Cada historia es una oportunidad para construir un producto más resistente.
Empiece pequeño. Elija una historia próxima y revise sus casos límite. Pida al equipo que desafíe el camino feliz. Es probable que encuentre oportunidades para mejorar la calidad del trabajo antes de que se escriba una sola línea de código.

